
Nonlinear Advantage
Recently, with the democratization of big open source fundation models such as Meta’s llama 2 or stable diffusion, many people gained interest in model pruning and quantization, desperately trying to cram big open source models on their old dying 1080ti. But there is also a theoretical question behind it: how compressible are deep learning models? Do we really need models as complex as they currently are, to be able do what we do?
From a theoretical perspective, traditional pruning methods are not the best way to answer this question: if we halve a network’s parameter count, is it really half as complex? This is we we decided to prune a model’s nonlinear units or layers, instead of model weights, as these are the components responsible for it’s complexity; this we can actually measure how `simple’ we can make a network, before it becomes unable to solve its assigned task.
In practise, we start with a fully trained network, and add a sparsity regularizer:
to the loss term, which pushes the slopes of the ReLU units towards 1.

A PReLU unit transitioning from ReLU to Linear state.
This way, as we can see below, some ReLU of the units in the network are linearized () in a short post-training phase, but the network can decide which ones to keep nonlinear.

Here, only a small proportion of nonlinear units remains active in the middle of the network.
Using this technique, we made a series of interesting observations:
-
Networks can be made surprisingly shallow (>90% on Cifar10 for a pruned ResNet56 w/ on average ~3.5 ReLU units) for their performance, especially for easier problems.
-
No matter the starting width or depth, for a fixed regularization weight , the network always shrinks to a `core network’ of the same shape.
-
Nonlinear advantage: Shallow networks extracted from pre-trained deep networks outperform shallow networks trained from scratch.
Especially the last one is quite fascinating, as there is not apparent reason for it! In the following experiment, we simply started the linearization process at different times during training, but always stop when the amount of linearized units in the network hits .
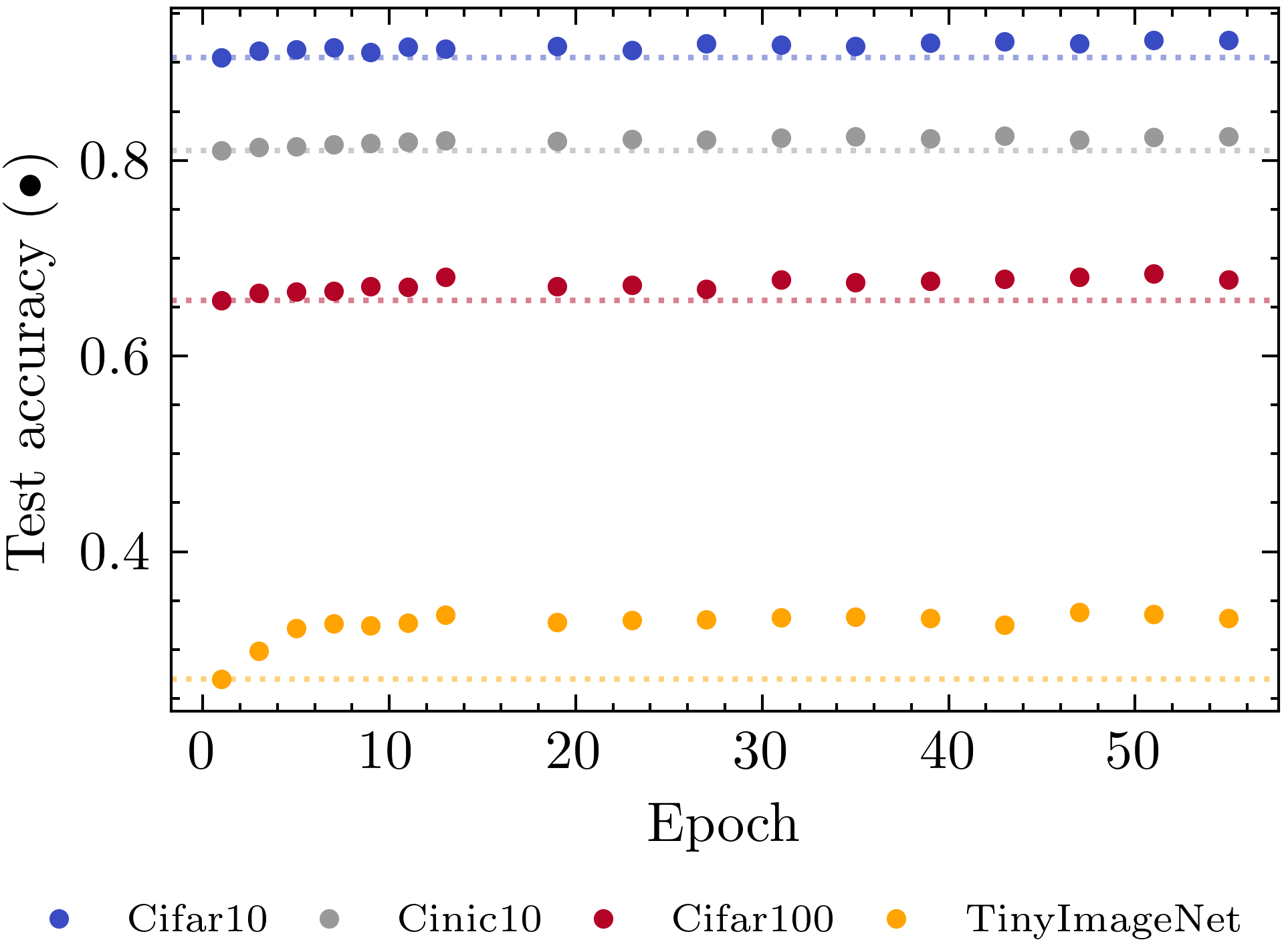
We see that earlier networks perform better, even through the expressivity of the final networks is exactly the same. This seems to imply that, for some reason, networks need most of their depth for early training, but not for their final solution! A viable hypothesis could be that networks need a vast hypothesis space in early training, in order to chose the one that fits the data. But so far, no simple explanation for this effect has been found. If you can find a good explanation for it - let me know!
For a more formal writeup, check out our paper Nonlinear Advantage: Trained Networks Might Not Be As Complex as You Think